by Pavel Holoborodko on July 2, 2016
There seems to be growing interest in how to detect user interrupt (Ctrl-C) inside compiled MEX library. The main difficulty is that TheMathWorks provides no official API to recognize and handle the situation.
As a workaround, Wotao Yin found undocumented function utIsInterruptPending which can be used to check if Ctrl-C was pressed. The most obvious usage pattern is to include calls to the function in lengthy computational code (loops, etc.) and exit the computations if needed. Collection of various improvements on using utIsInterruptPending can be found in recent Yair Altman’s post.
Unfortunately, despite all these efforts the most important issue was not addressed and was not resolved up to date – asynchronous handling of Ctrl-C.
In order to respond to user interrupt, source code of the MEX module have to be changed to include utIsInterruptPending calls. Every sub-module, every loop of the code needs to be revised. This is not only time-consuming and error-prone process, but also makes pure computational code dependent on MEX API.

Most importantly, it is not possible to do all the modifications if MEX uses third-party libraries with no access to its source code.
The ideal solution would be to avoid any of the changes to computational code in MEX. Here we propose one of the ways to do so.
Read More
by Pavel Holoborodko on May 19, 2016
New version of toolbox includes a lot of updates released over the course of six months. We focused on speed, better support of sparse matrices, special functions and stability. Upgrade to the newest version is highly recommended as it contains critical updates for all platforms.
Short summary of changes:
- The Core
by Pavel Holoborodko on May 13, 2016
Recent works citing the toolbox:
- J. Rashidinia, G.E. Fasshauer, M. Khasi, A stable method for the evaluation of Gaussian radial basis function solutions of interpolation and collocation problems, Computers & Mathematics with Applications, Available online 21 May 2016.
- Aprahamian M., Theory and Algorithms for Periodic Functions of Matrices, PhD Thesis, The University of Manchester, May 16, 2016.
- Berljafa M., Güttel S., The FEAST algorithm for Hermitian eigenproblems, Accessed on May 12, 2016.
- S. Melkoumian, B. Protas, Drift Due to Two Obstacles in Different Arrangements, Journal of Theoretical and Computational Fluid Dynamics, May 6, 2016, Pages 1–14.
- Jussi Lehtonen, Geoff A. Parker and Lukas Schärer, Why anisogamy drives ancestral sex roles. Evolution: International Journal on Organic Evolution, May 5, 2016.
- M. Rahmanian, b, R.D. Firouz-Abadia, E. Cigeroglub. Free vibrations of moderately thick truncated conical shells filled with quiescent fluid, Journal of Fluids and Structures, Volume 63, May 2016, Pages 280–301.
- Isaac S. Klickstein, Afroza Shirin, and Francesco Sorrentino. Feasible Strategies to Target Complex Networks, Department of Mechanical Engineering, University of New Mexico, April 14, 2016.
- Z. Qu, D. Tkachenko, Global Identification in DSGE Models Allowing for Indeterminacy, April 5, 2016.
Previous issues: digest v.5, digest v.4, digest v.3 and digest v.2.
by Pavel Holoborodko on May 12, 2016
Introduction
In previous posts we studied accuracy of computation of modified Bessel functions: K1(x), K0(x), I0(x) and I1(x). In spite of the fact that modified Bessel functions are easy to compute (they are monotonous and do not cross x-axis) we saw that MATLAB provides accuracy much lower than expected for double precision. Please refer to the pages for more details.
Today we will investigate how accurately MATLAB computes Bessel functions of the first and second kind Yn(x) and Jn(x) in double precision. Along the way, we will also check accuracy of the commonly used open source libraries.
")
Having extended precision routines, accuracy check of any function needs only few commands:
% Check accuracy of sine using 1M random points on (0, 16]
>> mp.Digits(34);
>> x = 16*(rand(1000000,1));
>> f = sin(x); % call built-in function for double precision sine
>> y = sin(mp(x)); % compute sine values in quadruple precision
>> z = abs(1-f./y); % element-wise relative error
>> max(z./eps) % max. relative error in terms of 'eps'
ans =
0.5682267303295349594044472141263213
>> -log10(max(z)) % number of correct decimal digits in result
ans =
15.89903811472552788729580391380739Computed sine values have ~15.9 correct decimal places and differ from ‘true’ function values by ~0.5eps. This is the highest accuracy we can expect from double precision floating-point arithmetic.
Read More
by Pavel Holoborodko on April 28, 2016
Signed zeros are important part of the IEEE754 standard for floating point arithmetic[1], commonly supported in hardware and in programming languages (C++[2], C[3], FORTRAN[4], etc.).
One of the areas where signed zeros play essential role is correct handling of branch cuts of special functions. In fact, it was one of the reasons why “negative zeros” were introduced in the first place[5].
The very unpleasant surprise is that MATLAB has poor support for this important feature.
I. Technically it allows user to create negative zeros:
>> x = -0
x =
0
>> 1/x
ans =
-InfThe minus sign is not displayed in front of zero (well-known issue of MATLAB) but second operation shows that x is indeed negative.
II. (Real zeros) Sign of real zero is ignored in operations where it plays important role:
% MATLAB/Double precision
>> atan(+0-1.5*1i)
ans =
1.5707963267949 - 0.80471895621705i
>> atan(-0-1.5*1i)
ans =
1.5707963267949 - 0.80471895621705i% MATLAB/Symbolic Math Toolbox (VPA)
>> atan(vpa('+0-1.5*i'))
ans =
-1.570796327 - 0.8047189562 i
>> atan(vpa('-0-1.5*i'))
ans =
-1.570796327 - 0.8047189562 iIn both cases sign of real zero is ignored, and the most amazingly is that different parts of MATLAB do not agree what sign zero has by default (VPA assumes zero is negative, the core function – zero is positive).
Read More
by Pavel Holoborodko on April 27, 2016
UPDATE (April 22, 2017): Timings for Mathematica 11.1 have been added to the table, thanks to test script contributed by Bor Plestenjak. I suggest to take a look at his excellent toolbox for multiparameter eigenvalue problems – MultiParEig.
UPDATE (November 17, 2016): All timings in table have been updated to reflect speed improvements in new version of toolbox (4.3.0). Now toolbox computes elementary functions using multi-core parallelism. Also we included timings for the the latest version of MATLAB – 2016b.
UPDATE (June 1, 2016): Initial version of the post included statement that newest version of MATLAB R2016a uses MAPLE engine for variable precision arithmetic (instead of MuPAD as in previous versions). After more detailed checks we have detected that this is not true. As it turned out, MAPLE 2016 silently replaced VPA functionality of MATLAB during installation. Thus we (without knowing it) tested MAPLE Toolbox for MATLAB instead of MathWorks Symbolic Math Toolbox. We apologize for misinformation. Now post provides correct comparison results with Symbolic Math Toolbox/VPA.
Thanks to Nick Higham, Massimiliano Fasi and Samuel Relton for their help in finding this mistake!
From the very beginning we have been focusing on improving performance of matrix computations, linear algebra, solvers and other high level algorithms (e.g. 3.8.0 release notes).
With time, as speed of advanced algorithms has been increasing, elementary functions started to bubble up in top list of hot-spots more frequently. For example the main bottleneck of the multiquadric collocation method in extended precision was the coefficient-wise power function (.^).
Thus we decided to polish our library for computing elementary functions. Here we present intermediate results of this work and traditional comparison with the latest MATLAB R2016b (Symbolic Math Toolbox/Variable Precision Arithmetic), MAPLE 2016 and Wolfram Mathematica 11.1.0.0.
Timing of logarithmic and power functions in 3.9.4.10481:
>> mp.Digits(34);
>> A = mp(rand(2000)-0.5);
>> B = mp(rand(2000)-0.5);
>> tic; C = A.^B; toc;
Elapsed time is 67.199782 seconds.
>> tic; C = log(A); toc;
Elapsed time is 22.570701 seconds.
Speed of the same functions after optimization, in 4.3.0.12057:
>> mp.Digits(34);
>> A = mp(rand(2000)-0.5);
>> B = mp(rand(2000)-0.5);
>> tic; C = A.^B; toc; % 130 times faster
Elapsed time is 0.514553 seconds.
>> tic; C = log(A); toc; % 95 times faster
Elapsed time is 0.238416 seconds.
Now toolbox computes 4 millions of logarithms in quadruple precision (including negative arguments) in less than a second!
Read More
by Pavel Holoborodko on February 22, 2016
UPDATE (December 2, 2017): We have found a workaround for the issue and included it into toolbox, this error shouldn’t appear for toolbox versions starting from 4.4.5.
Lately we have been receiving increasing number of reports from users who encounter the following error when trying to use toolbox on GNU Linux version of MATLAB:
>> addpath('/home/user/Documents/AdvanpixMCT-3.9.1.10015');
>> mp.Info
Invalid MEX-file '/home/user/Documents/AdvanpixMCT-3.9.1.10015/mpimpl.mexa64':
dlopen: cannot load any more object with static TLS
Error in mp.Info (line 196)
mpimpl(4);The error has no relation to our toolbox – it is long standing issue with MATLAB itself, known at least since R2012b release. Overview of the problem can be found on stackoverflow or in our brief explanation below[1].
Here we focus on how to fix the issue in few simple steps.
Read More
by Pavel Holoborodko on February 14, 2016
MEX API provides two functions for proper handling of erroneous situations: mexErrMsgTxt and mexErrMsgIdAndTxt. Both show error message, interrupt execution of a MEX module and return to MATLAB immediately.
Under the hood the functions are implemented through C++ exceptions. The reason for such design choice is unclear. Throwing C++ exceptions across module boundary (e.g. from dynamic library to host process) is unsafe and generally considered as bad practice in software design. Exceptions are part of C++ run-time library and different versions of it might have incompatible implementations.
Read More
by Pavel Holoborodko on January 5, 2016
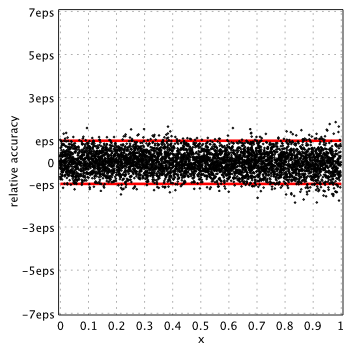
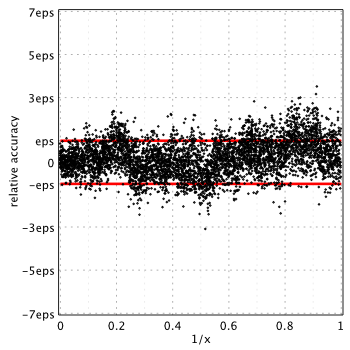
In this post we will consider minimax rational approximations used for computation of modified Bessel functions of the second kind –  . We will follow our usual workflow – we study properties of the existing methods and then propose our original approximations optimized for computations with double precision.
. We will follow our usual workflow – we study properties of the existing methods and then propose our original approximations optimized for computations with double precision.
We try to keep the post brief and stick to results. Detailed description of our methodology can be found in previous reports of the series: K0(x), I0(x) and I1(x).
In their pioneering work[1], Blair & Russon proposed the following approximation forms for  :
:
All software libraries relying on rational approximations for computing use (1) and (2) with small variations in coefficients of polynomials  and
and  .
.
Relative accuracy shown below is measured in terms of machine epsilon ( eps = 2-52 ˜ 2.22e-16) against “true” values of the function computed in quadruple precision by Maple. Red lines show natural limits for relative error we expect for double precision computations.
Blair & Russon[1], Boost 1.59.0[2] and SPECFUN 2.5[3]
Boost and SPECFUN use the same coefficients from original report of Blair & Russon.
Read More
by Pavel Holoborodko on January 5, 2016
Recent papers with references to toolbox:
Books
Papers
- Isaac S. Klickstein, Afroza Shirin, and Francesco Sorrentino. Optimal Target Control of Complex Networks, Department of Mechanical Engineering, University of New Mexico, March 25, 2016.
- Nicholas J. Higham and E. Deadman. A Catalogue of Software for Matrix Functions. Version 2.0. January 2016.
- M. Aprahamian, N.J. Higham, Matrix Inverse Trigonometric and Inverse Hyperbolic Functions: Theory and Algorithms, 20 January 2016
- S. Bangay, G. Beliakov, On the fast Lanczos method for computation of eigenvalues of Hankel matrices using multiprecision arithmetics, Numerical Linear Algebra with Applications, 22 January 2016.
- T. M. Bruintjes, A. B. J. Kokkeler, and G. J. M. Smit, Asymmetric Shaped Pattern Synthesis for Planar Antenna Arrays, 28 December 2015.
- S. Melkoumian, B. Protas, Drift Due to Two Obstacles in Different Arrangements, 22 November 2015.
- Z. Drmac, SVD of Hankel matrices in Vandermonde-Cauchy product form, Electronic Transactions on Numerical Analysis. Volume 44, pp. 593–623, 2015.
- A.H-D. Cheng, C.A. Brebbia, Boundary Elements and Other Mesh Reduction Methods XXXVIII, Volume 61 of WIT Transactions on Modelling and Simulation, WIT Press, 16 November, 2015.
- K. Tanaka, T. Okayama, M. Sugihara, Potential theoretic approach to design of highly accurate formulas for function approximation in weighted Hardy spaces, 14 November 2015.
- A. Nishiyama, K. Nakashima, A. Matsuba, M. Misono, Doppler-free two-photon absorption spectroscopy of rovibronic transition of naphthalene calibrated with an optical frequency comb, Journal of Molecular Spectroscopy, 9 October 2015.
- J. Abaffy, S. Fodor, Reorthogonalization Methods in ABS Classes, Acta Polytechnica Hungarica Vol. 12, No. 6, 2015.
- Kestyn J., Polizzi E., Tang PTP., FEAST Eigensolver for non-Hermitian Problems, June 15, 2015.
- Hiptmair R., Moiola A., Perugia I., A Survey of Trefftz Methods for the Helmholtz Equation, June 15, 2015.
- Berljafa M., Güttel S., The RKFIT algorithm for nonlinear rational approximation, June 13, 2015.
Previous issues: digest v.4, digest v.3 and digest v.2.
 :
:
 :
: